


Qu'est-ce qu'Amazon Redshift ?
Amazon Redshift est un service serverless de stockage et d'analyse de données à grande échelle. Il combine la puissance du traitement SQL avec la capacité de gérer de grands volumes de données structurées et semi-structurées, tout en optimisant les coûts.
- Traitement de grands volumes de données.
- Business Intelligence et visualisation des données.
- Analyse de données en temps réel pour la prise de décision.
- Mise à l'échelle des applications web et mobiles.
Avantages du service :
L'architecture d'Amazon Redshift permet d'exécuter des requêtes rapidement et efficacement, offrant ainsi des performances élevées. Le service prend également en charge les tâches d'administration telles que les sauvegardes et la supervision du cluster, ce qui réduit la charge opérationnelle des équipes. Enfin, son intégration avec les autres services AWS facilite l'exploitation de données provenant de sources telles qu'Amazon S3 ou AWS Glue. Pour la création de tableaux de bord et de rapports interactifs, Amazon Redshift s'intègre naturellement avec des outils de visualisation comme Amazon QuickSight.
Amazon Redshift Spectrum
Cette approche offre une grande flexibilité et permet d'analyser des données réparties sur plusieurs emplacements de stockage, sans duplication des données.
Importance du stockage et de l'analyse des données
Enfin, elle améliore l'efficacité opérationnelle en optimisant l'utilisation des ressources, en réduisant les coûts et en renforçant la rentabilité globale de l'organisation.
Implémentation d'Amazon Redshift
Stratégie de distribution et de tri : Amazon Redshift stocke les données sous forme de colonnes et les répartit entre les différents nœuds afin d'assurer un traitement parallèle performant. Le choix de la stratégie de distribution (par clé, distribution complète ou par hachage) est essentiel pour optimiser les performances. De même, la définition des clés de tri améliore l'exécution des requêtes nécessitant des opérations de lecture intensives.
Chargement et transformation des données
Le chargement et la transformation des données constituent une étape essentielle pour garantir que les données soient disponibles et prêtes à être analysées dans un cluster Amazon Redshift.
Extraction et transformation des données
Ce processus peut inclure la suppression des données redondantes ou erronées, ainsi que leur transformation afin qu'elles respectent le schéma et les contraintes des tables Amazon Redshift. Ces opérations peuvent être réalisées à l'aide d'outils ETL tels qu'AWS Glue ou AWS Data Pipeline.
Formats de fichiers pris en charge
- CSV
- JSON
- Parquet et Avro
- ORC (Optimized Row Columnar)
- Delta
Chargement des données dans Amazon Redshift
- Copie depuis des fichiers locaux ou Amazon S3 : permet de charger des données stockées localement ou dans des fichiers hébergés sur Amazon S3.
- Utilisation d'outils ETL : permet d'automatiser et de simplifier les processus de chargement et de transformation des données.
- Chargement incrémental : plutôt que de charger l'ensemble des données en une seule fois, il est recommandé de procéder à des chargements progressifs.
Validation et supervision des données
Cette étape consiste à exécuter des requêtes et des contrôles afin de vérifier que les données ont été correctement chargées et qu'elles respectent les règles ainsi que les contraintes définies dans le schéma des tables.
Requêtes et analyse des données
L'analyse des données est essentielle pour exploiter pleinement les informations stockées dans Amazon Redshift. Grâce à SQL, il est possible d'exécuter facilement différents types de requêtes :
- Requêtes analytiques : permettent d'analyser de grands volumes de données après leur traitement.
- Requêtes complexes : Amazon Redshift prend en charge les jointures, les agrégations, les fonctions analytiques et les sous-requêtes. Il est ainsi possible de combiner des données provenant de plusieurs tables, d'effectuer des calculs avancés et d'extraire des informations à forte valeur ajoutée.
- Requêtes programmatiques : permettent d'accéder aux données via des API, facilitant ainsi l'intégration avec des applications et des processus automatisés.
Monitoring et optimisation des performances
Le monitoring du cluster peut être réalisé à l'aide d'outils tels que la console AWS, qui permet de suivre l'utilisation du CPU, de l'espace disque, le volume des données transférées ainsi que d'autres métriques de performance.
Pour optimiser les performances, Amazon Redshift s'appuie sur des statistiques et des métadonnées afin d'améliorer la précision de l'optimiseur de requêtes. En cas de baisse des performances, il est possible d'optimiser le schéma des tables, de réécrire les requêtes SQL ou de revoir les clés de distribution et de tri.
Il est également recommandé d'effectuer une maintenance régulière, incluant l'application des correctifs, la mise à jour des versions logicielles et l'optimisation de la configuration du cluster afin de garantir des performances optimales.
Architecture générale
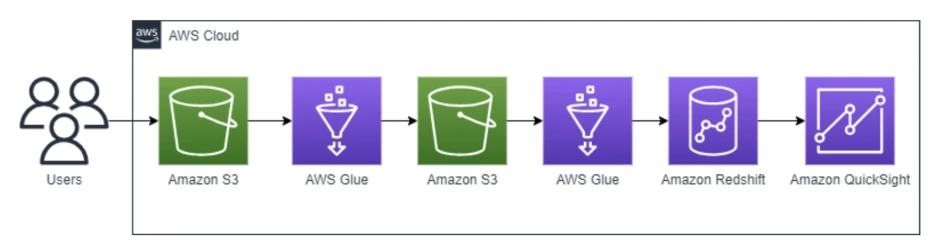
Dans cette architecture, les données sont stockées dans un Data Lake sur Amazon S3, puis cataloguées à l'aide d'AWS Glue. Une fois préparées et structurées, elles sont chargées dans Amazon Redshift pour les traitements analytiques. Enfin, Amazon QuickSight est utilisé comme solution de Business Intelligence et de visualisation afin de créer des tableaux de bord et des rapports à forte valeur ajoutée.
Conclusions
Notre expérience acquise à travers des projets d'envergure en Amérique du Sud est aujourd'hui mise au service des entreprises suisses. Nous avons notamment développé des plateformes d'analytics reposant sur Amazon S3, Amazon Redshift et un Data Lake alimenté par plusieurs sources de données. Cette architecture a permis de créer des tables de référence, de structurer les données et de produire des rapports décisionnels. Les résultats obtenus incluent une réduction des coûts pouvant atteindre 80 % ainsi qu'une amélioration de 20 % des performances des jobs exécutés en parallèle.
Nos derniers contenus
Découvrez les nouveautés dans notre entreprise !