


À la découverte d'AWS Glue
- Exploration et structuration des données.
- Transformation, préparation et nettoyage des données en vue de leur analyse.
- Conception et orchestration de pipelines de données.
Avantages du service :
AWS Glue permet de se connecter à plus de 70 sources de données différentes et de gérer l'ensemble des métadonnées dans un catalogue centralisé. Il offre la possibilité de créer, d'exécuter et de superviser visuellement des pipelines ETL (Extract, Transform, Load) destinés à alimenter des Data Lakes. Les données cataloguées peuvent ensuite être interrogées immédiatement avec Amazon Athena, Amazon EMR ou Amazon Redshift Spectrum.
AWS Glue contribue également à optimiser les coûts. En tant que service entièrement administré, il élimine la nécessité de gérer une infrastructure dédiée et réduit les charges opérationnelles. Son modèle de mise à l'échelle automatique permet de ne payer que les ressources réellement consommées. Enfin, son intégration native avec des services tels qu'Amazon S3 et Amazon Redshift permet d'optimiser les coûts de stockage et de traitement des données grâce à des architectures performantes et économiques.
Accès au service AWS Glue
Ces différentes interfaces permettent d'utiliser AWS Glue selon vos préférences, que ce soit via une interface web, un environnement graphique, la ligne de commande ou l'API.
Gestion de la sécurité
AWS Glue propose plusieurs fonctionnalités permettant de sécuriser les données et les ressources :
Contrôle des accès : AWS Identity and Access Management (IAM) permet de définir précisément les autorisations des utilisateurs, des groupes et des rôles, ainsi que les actions qu'ils peuvent effectuer dans AWS Glue.
Chiffrement des données au repos : AWS Glue prend en charge le chiffrement des données stockées dans ses bases de données et dans le Data Catalog à l'aide d'AWS Key Management Service (KMS).
Chiffrement des données en transit : les communications entre les différents composants d'AWS Glue sont protégées par le protocole SSL/TLS afin de sécuriser les échanges de données.
Sécurité du Data Catalog : des politiques d'accès permettent de contrôler les autorisations sur les métadonnées afin que seuls les utilisateurs autorisés puissent les consulter ou les modifier.
Supervision et audit : grâce à son intégration avec AWS CloudTrail, AWS Glue enregistre les opérations effectuées dans votre environnement AWS, facilitant ainsi l'audit, la traçabilité et la détection d'événements de sécurité.
Analyse de données
-
- Étape 1 : Préparation des données
- Préparez les données en les extrayant depuis différentes sources telles que des bases de données, des services de stockage Cloud ou des fichiers. AWS Glue permet de découvrir et de connecter plus de 70 sources de données afin de simplifier cette étape.
-
- Étape 2 : Création d'un Data Catalog
- Créez un catalogue de données centralisé pour stocker et gérer les métadonnées. Cela facilite l'organisation, la découverte et l'exploitation des données.
-
- Étape 3 : Création des pipelines de données
- Concevez des pipelines ETL (Extract, Transform, Load) afin de transformer efficacement les données. Ces traitements peuvent inclure le nettoyage, le filtrage, l'agrégation ou toute autre transformation nécessaire avant l'analyse.
-
- Étape 4 : Configuration et exécution des traitements AWS Glue
- Configurez et exécutez les traitements AWS Glue afin de transformer les données et de les charger dans le Data Lake ou le Data Warehouse de votre choix. Ces traitements peuvent être administrés depuis la console AWS Glue, AWS Glue Studio ou via l'API AWS Glue.
-
- Étape 5 : Analyse des données
- Une fois les données préparées et chargées, utilisez des services tels qu'Amazon Athena, Amazon Redshift Spectrum ou Amazon EMR pour interroger et analyser les données cataloguées
-
Architecture générale
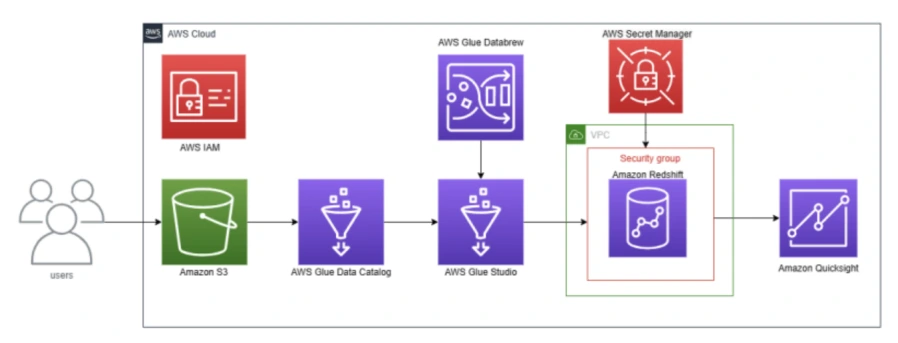
Le flux de cette architecture débute par le stockage des données dans Amazon S3. AWS Glue Data Catalog et AWS Glue Studio sont ensuite utilisés pour cataloguer, préparer et transformer les données. Celles-ci sont ensuite chargées dans Amazon Redshift, qui sert de Data Warehouse pour les analyses. Enfin, Amazon QuickSight permet de visualiser les données et d'en extraire des informations pertinentes à partir des données stockées dans Amazon Redshift.
Conclusions
Grâce à ses capacités de découverte et de catalogage des données, à l'automatisation des traitements ETL, à son intégration avec les principaux services d'analyse AWS et à la gestion centralisée des métadonnées, AWS Glue permet aux organisations d'exploiter pleinement leurs données et de prendre des décisions plus rapidement et en toute confiance.