


À la découverte d'Amazon Athena
Amazon Athena est un service d'analyse interactif, serverless et facturé à l'usage, basé sur des technologies open source. L'un de ses principaux avantages est sa compatibilité avec les formats de fichiers et de tables ouverts.
Idéal pour de nombreux cas d'usage :
- Création de solutions d'analyse interactives.
- Analyse des journaux des services AWS envoyés vers Amazon S3.
- Interrogation de données provenant de sources relationnelles, non relationnelles, orientées objets ou personnalisées.
- Exécution de requêtes SQL ad hoc interactives sur les journaux web stockés dans Amazon S3.
Avantages du service :
Amazon Athena permet aux différentes équipes de l'entreprise d'accéder aux données structurées stockées dans le Data Lake sur Amazon S3, de les organiser et d'exécuter des requêtes SQL afin de créer des vues analytiques et des rapports mis à jour en temps réel.
Comment exécuter une requête avec Amazon Athena ?
- Étape 1 : Accéder à la console AWS
- Étape 2 : Ouvrir Amazon Athena
- Étape 3 : Sélectionner la base de données
- Étape 4 : Cliquer sur « New Query »
- Étape 5 : Saisir la requête
- Étape 6 : Exécuter la requête
- Étape 7 : Analyser les résultats
- Étape 8 : Télécharger les résultats si nécessaire
Gestion de la sécurité
Enfin, les politiques de buckets Amazon S3 jouent un rôle essentiel dans la gestion fine des autorisations attribuées aux utilisateurs, aux groupes et aux rôles IAM. Elles permettent de contrôler l'accès aux données, les actions autorisées ainsi que les objets pouvant être manipulés.
Intégration d'Amazon Athena avec AWS Glue
La integración de AWS Glue con Amazon Athena proporciona un catálogo centralizado de metadatos. Esto permite una gestión más sencilla de los metadatos asociados a los datos consultados mediante Athena. Además, las capacidades ETL de Glue pueden utilizarse para transformar datos o convertirlos en columnas.
De tal manera, la optimización de consultas permite recopilar estadísticas sobre los datos almacenados en S3, como tamaños de archivos y distribuciones de valores. Una vez finalizado, Athena utiliza dichas estadísticas para obtener consultas más rápidas, conseguir un menor consumo de recursos y reducir costos en el procesamiento de datos.
Data Lake
Cette intégration améliore également les performances des requêtes en collectant des statistiques sur les données stockées dans Amazon S3, telles que la taille des fichiers et la distribution des valeurs. Athena exploite ensuite ces informations pour accélérer l'exécution des requêtes, réduire la consommation de ressources et optimiser les coûts de traitement des données.
Création d'un Data Lake avec Amazon Athena :
Appliquez des contrôles d'accès adaptés afin de protéger les données de votre Data Lake. Les politiques Amazon S3, les autorisations IAM et les permissions AWS Lake Formation permettent de sécuriser l'accès aux données.
Architecture générale
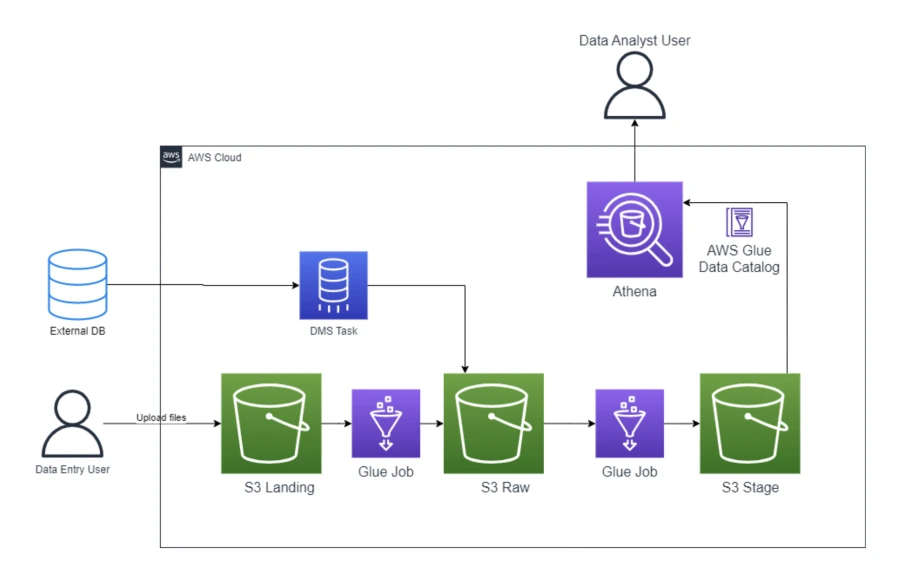
Cette architecture présente une vue d'ensemble d'un Data Lake sur AWS. Les données sont stockées dans Amazon S3, puis cataloguées et structurées à différentes étapes à l'aide d'AWS Glue. Les utilisateurs peuvent ensuite interroger ces données et réaliser leurs analyses métier grâce à Amazon Athena.
Conclusions
Amazon Athena est un service performant qui permet d'exécuter des requêtes ad hoc de manière simple et efficace. Grâce à son modèle de facturation à l'usage, il offre la possibilité d'analyser de grands volumes de données stockées dans Amazon S3. Son intégration avec AWS Glue facilite également la création d'un Data Lake, tout en permettant de sécuriser les données grâce aux mécanismes de protection proposés par AWS. En résumé, Amazon Athena constitue une solution performante pour l'analyse de données et la gestion d'un Data Lake sur Amazon Web Services.
Nos derniers contenus
Découvrez les nouveautés dans notre entreprise !